|
I am a full Professor at Xi'an Jiaotong University. I work on
computer vision and machine learning.
I got my Bachelor degrees from Tsinghua University and
Peking University.
I did my PhD at Tsinghua University and my Postdoc at
Carnegie Mellon University.
Email / Bio / Google Scholar |

|
Past News
|
|
|
|
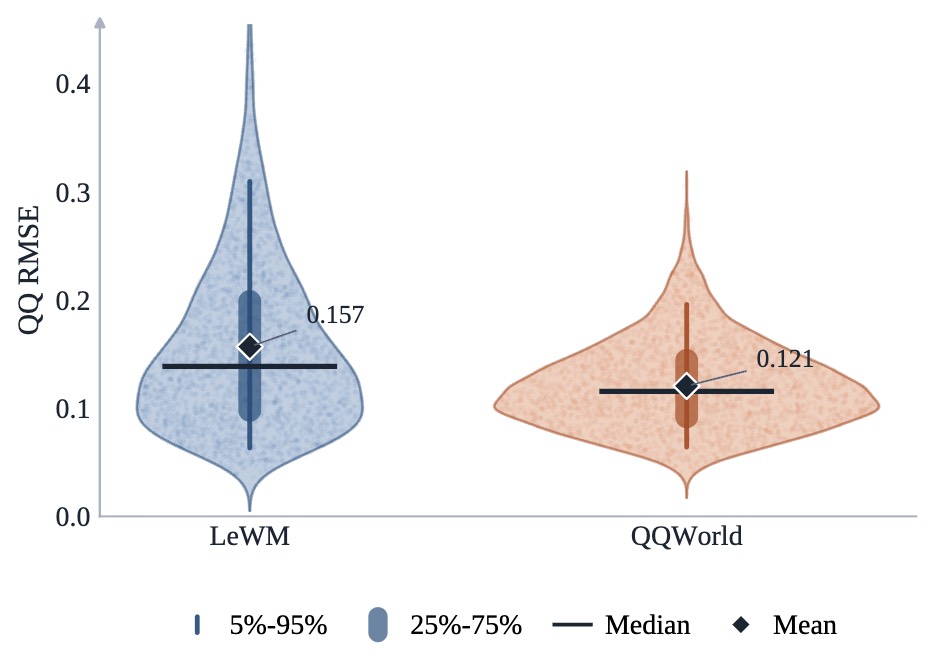
Zhoushun Yu, Xiaoyu Hu, Xiangyu Xu arXiv preprint, 2026 Paper We improve latent world models with a quantile-quantile matching objective that aligns projected latent samples with rank-matched Gaussian quantiles, boosting planning success. |
|
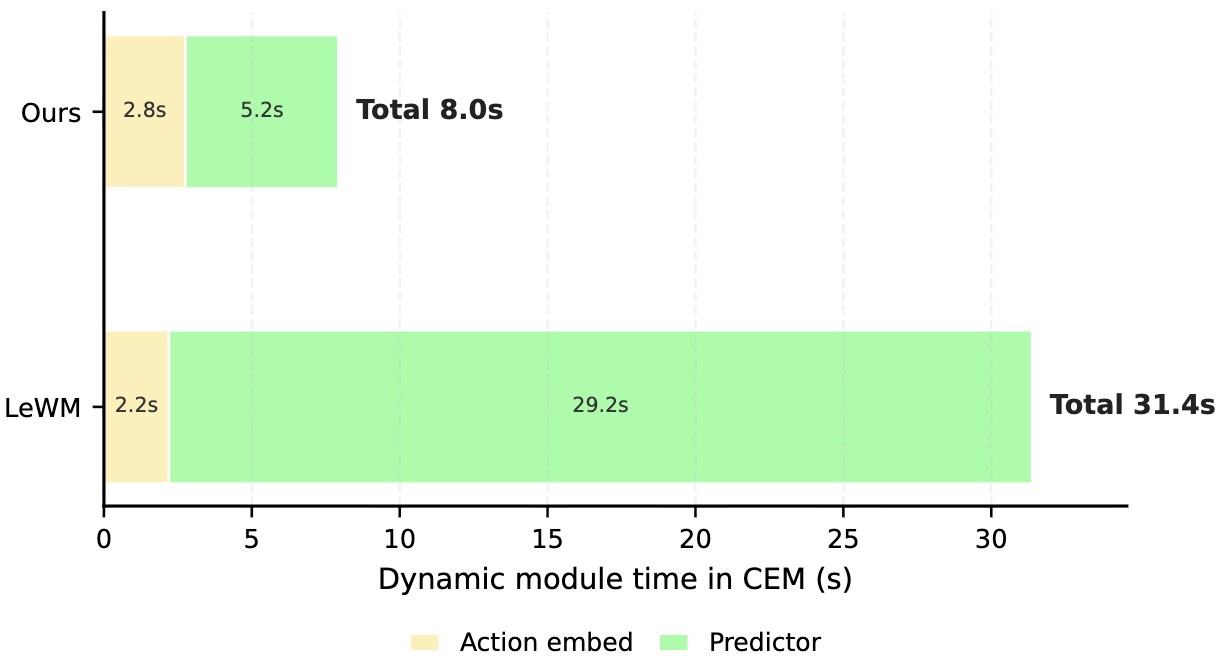
Yuntian Gao, Xiangyu Xu arXiv preprint, 2026 Paper We replace repeated local rollout with action-prefix prediction, enabling parallel evaluation of action sequences for faster and more accurate visual planning. |
|
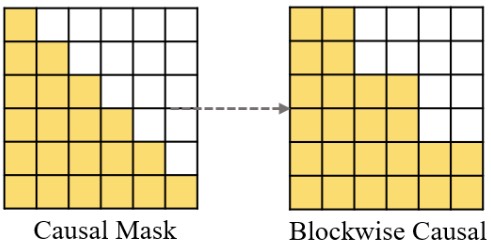
Ruiheng Wang, Shuanghao Bai, Haoran Zhang, Badong Chen, Xiangyu Xu arXiv preprint, 2026 Paper We convert pretrained autoregressive VLA models into block-level discrete diffusion policies, enabling parallel denoising and KV-cache reuse for faster robotic control. |

|
Jianlei Chang, Ruofeng Mei, Wei Ke, Xiangyu Xu AAAI Conference on Artificial Intelligence (AAAI), 2026 Paper | Project We propose an equivariant flow matching framework for robot policy learning, significantly improving sampling speed and data efficiency. |
|
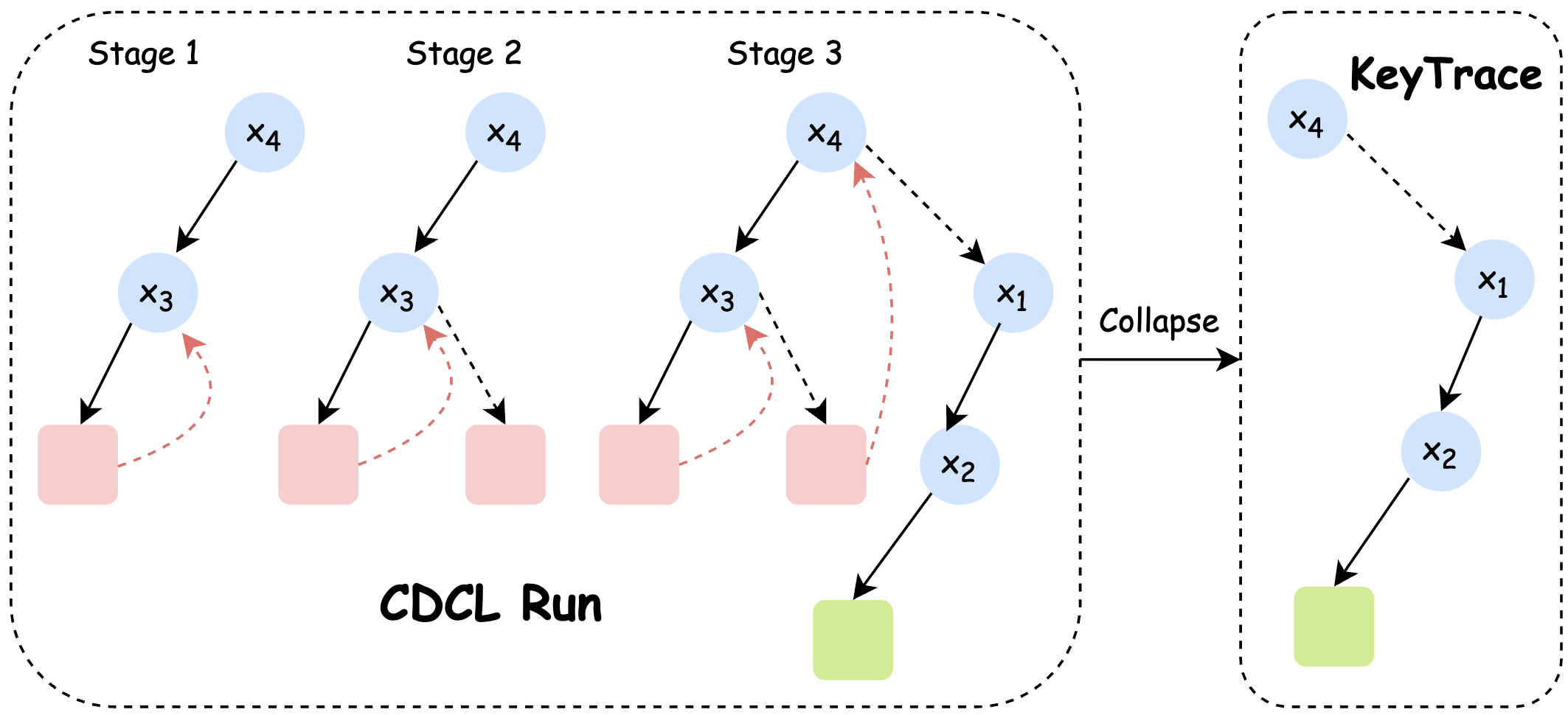
Zewei Zhang, Huan Liu, Yuanhao Yu, Jun Chen, Xiangyu Xu International Conference on Learning Representations (ICLR), 2026 Paper Our ImitSAT learns branching policies for boolean satisfiability solvers by imitating expert demonstrations. |

|
Chengqi Li, Zhihao Shi, Yangdi Lu, Wenbo He, Xiangyu Xu Conference on Neural Information Processing Systems (NeurIPS), 2025 (Spotlight) Paper We propose dual consistency regularization for robust 3D Gaussian Splatting in the wild. |
|
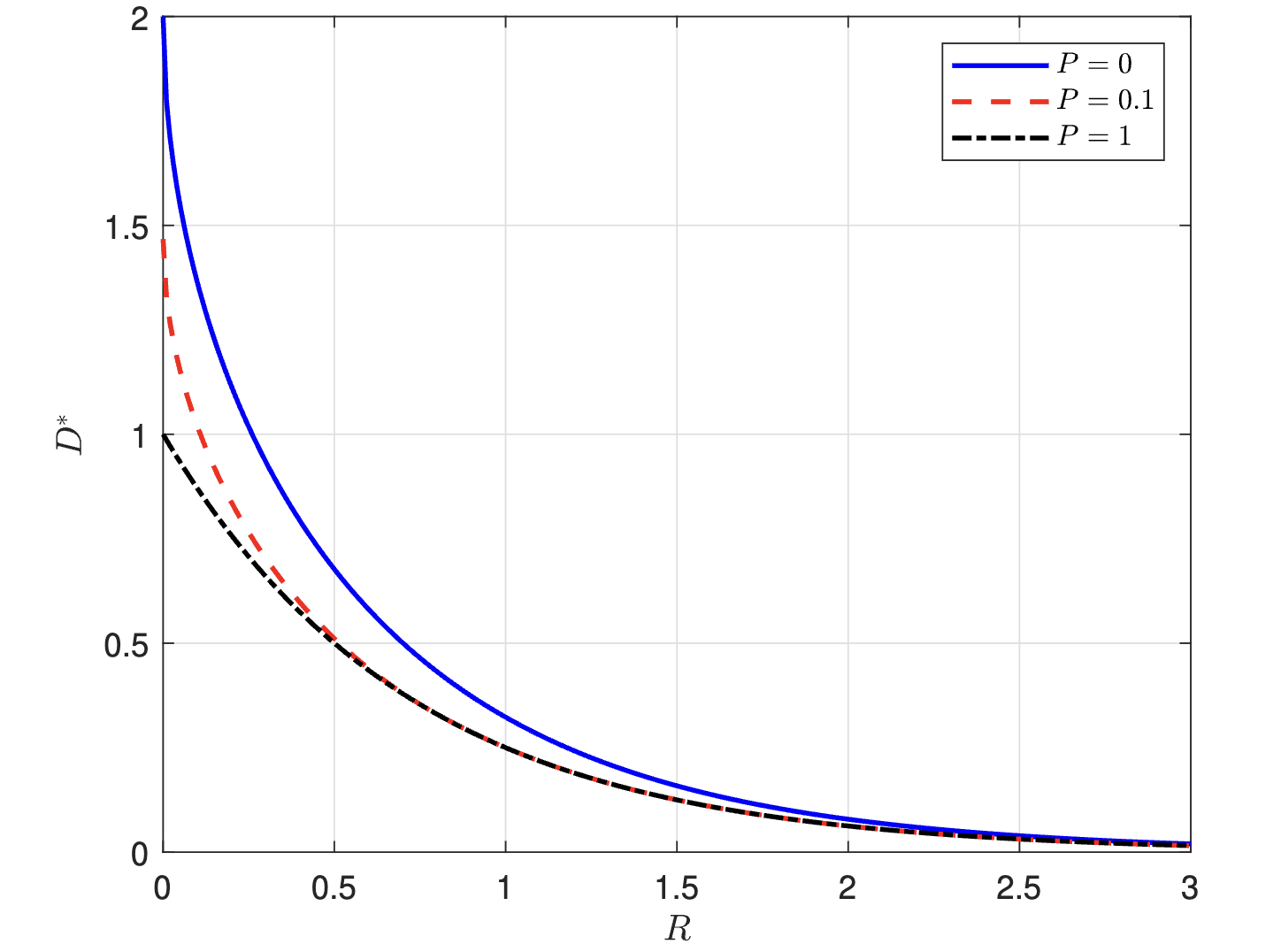
Xiqiang Qu, Jun Chen, Lei Yu, and Xiangyu Xu IEEE Transactions on Information Theory (TIT), 2025 Paper We develop a rate-distortion-perception theory under the Wasserstein-2 distance, with explicit Gaussian formulas and shared randomness. |
|
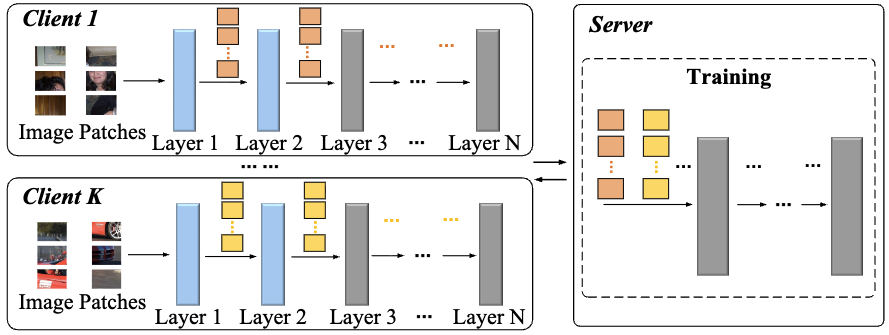
Meihan Wu, Tao Chang, Cui Miao, Jie Zhou, Chun Li, Xiangyu Xu, Ming Li, Xiaodong Wang International Conference on Computer Vision (ICCV), 2025 Paper We propose a hierarchical federated framework for full-parameter ViT training on edge devices. |
|
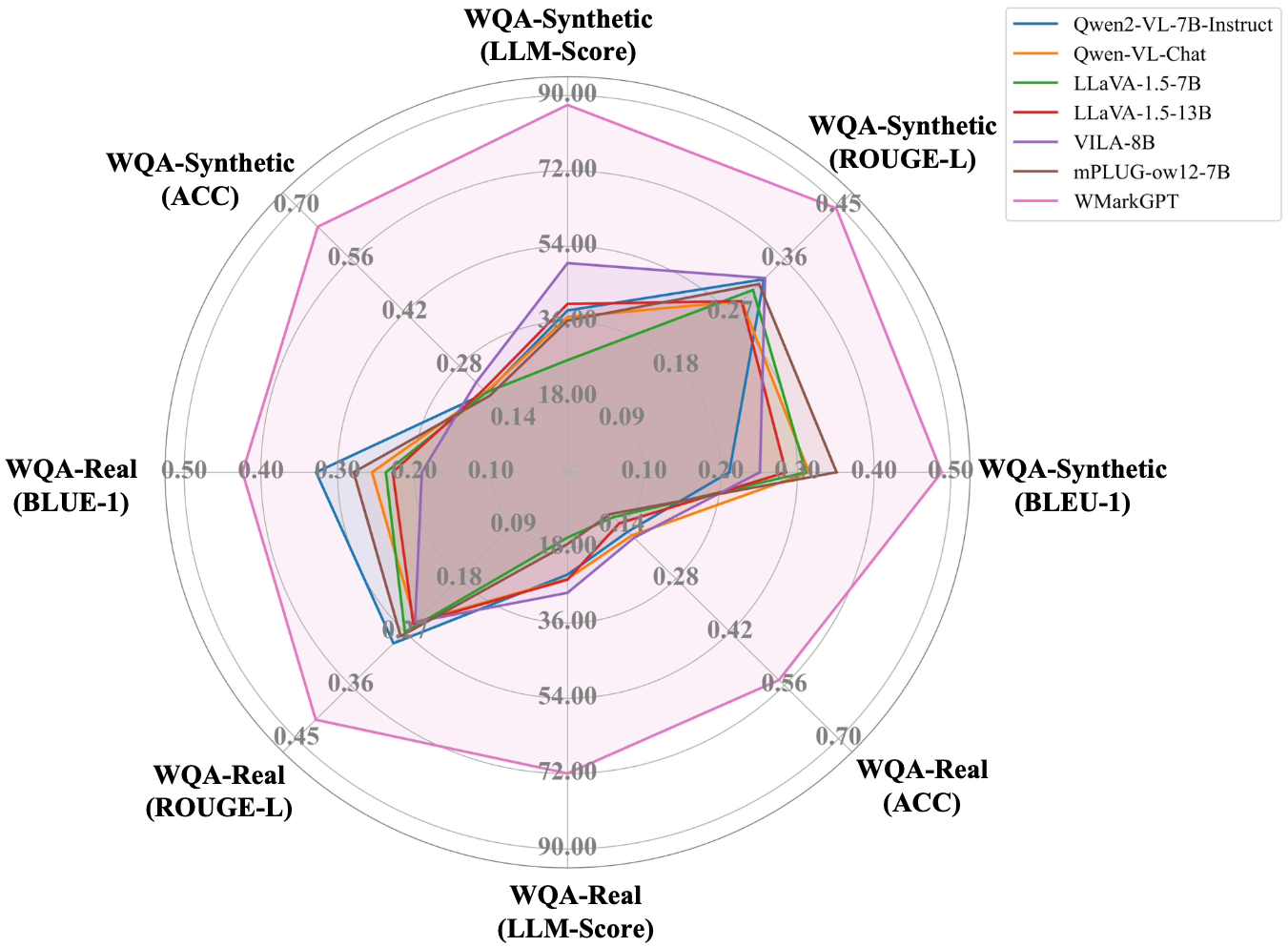
Songbai Tan, Xuerui Qiu, Gang Xu, Linrui Xu, Xiangyu Xu, Huiping Zhuang, Ming Li, Fei Yu International Conference on Machine Learning (ICML), 2025 Paper We build a multi-modal large language model for watermarked image understanding. |


|
Zewei Zhang, Huan Liu, Jun Chen, Xiangyu Xu International Conference on Learning Representations (ICLR), 2025 Paper | Project We present a new framework for drag editing with diffusion models. |

|
Jiabin Liang, Lanqing Zhang, Zhuoran Zhao, Xiangyu Xu SIGGRAPH Asia, 2024 Paper | Project We combine Level of Detail (LoD) with NeRF. |


|
Chengxu Liu, Xuan Wang, Xiangyu Xu, Ruhao Tian, Shuai Li, Xueming Qian, Ming-Hsuan Yang Computer Vision and Pattern Recognition Conference (CVPR), 2024 Paper We propose learnable motion-adaptive filters for blind image deblurring. |


|
Xiangyu Xu, Lijuan Liu, Shuicheng Yan IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2024 Paper | Project We propose a very simple Transformer for 3D human shape and pose estimation from a single image, which achieves SOTA accuracy with high efficiency in parameter and computation. |

|
Ming Li, Pan Zhou, Jia-Wei Liu, Jussi Keppo, Min Lin, Shuicheng Yan, Xiangyu Xu✉ International Journal of Computer Vision (IJCV), 2024 Paper | Project Text-to-3D generation without per-prompt training, taking only under a second. |


|
Stefan Lionar, Xiangyu Xu✉, Min Lin, Gim Hee Lee Conference on Neural Information Processing Systems (NeurIPS), 2023 Paper | Project We achieve new SOTA for single-view 3D reconstruction on CO3D. |

|
Lijuan Liu*, Xiangyu Xu*, Zhijie Lin*, Jiabin Liang*, Shuicheng Yan ACM Transactions on Graphics (SIGGRAPH Asia), 2023 Paper | Code | New Scientist We present the first solution for sewing pattern reconstruction from a single image. |
|
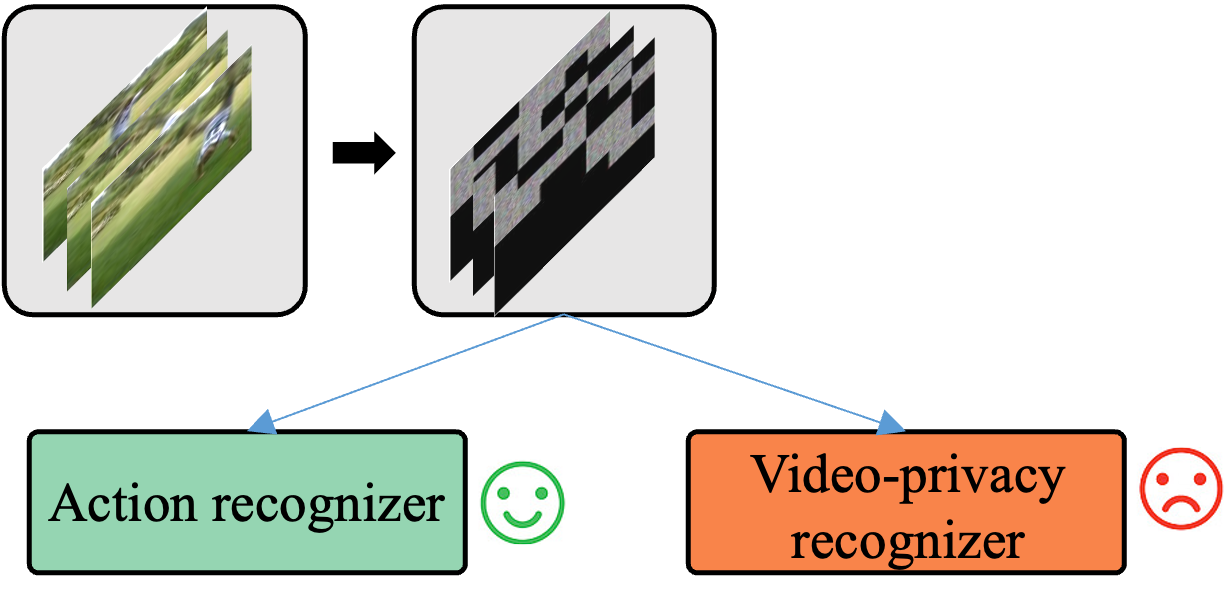
Ming Li, Xiangyu Xu, Hehe Fan, Pan Zhou, Jun Liu, Jia-Wei Liu, Jiahe Li, Jussi Keppo, Mike Zheng Shou, Shuicheng Yan International Conference on Computer Vision (ICCV), 2023 Paper | Code We explore privacy-preserving action recognition from a spatio-temporal perspective. |
|
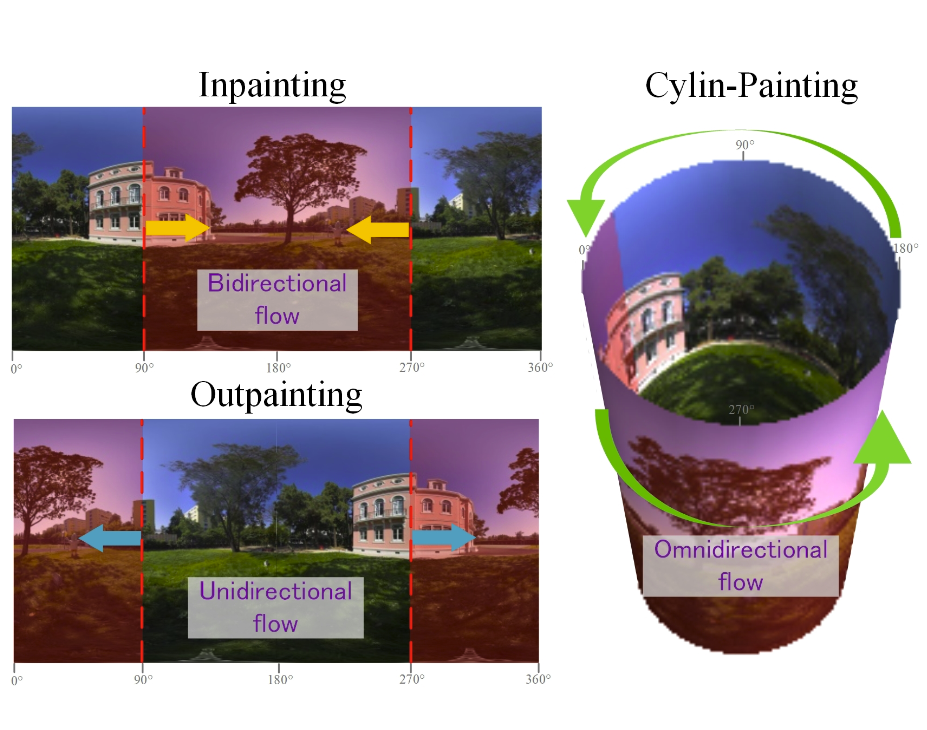
Kang Liao, Xiangyu Xu, Chunyu Lin, Wenqi Ren, Yunchao Wei, Yao Zhao IEEE Transactions on Image Processing (TIP), 2023 Paper | Code We propose a cylinder-style convolution for completing panoramic views. |


|
Kelvin C.K. Chan, Xiangyu Xu, Xintao Wang, Jinwei Gu, and Chen Change Loy IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2022 Paper | Code We develop a lighter version of GLEAN. |


|
Mingfei Chen, Jianfeng Zhang, Xiangyu Xu✉, Lijuan Liu, Yujun Cai, Jiashi Feng, Shuicheng Yan European Conference on Computer Vision (ECCV), 2022 Paper | Code We present an SMPL-based NeRF for multi-view human synthesis, which is efficient and generalizable to unseen subjects and sparse views. |


|
Zhihao Shi*, Xiangyu Xu*✉, Xiaohong Liu, Jun Chen, Ming-Hsuan Yang Computer Vision and Pattern Recognition Conference (CVPR), 2022 Paper | Code We present the first Transformer architecture for video frame interpolation. |


|
Kelvin C.K. Chan, Shangchen Zhou, Xiangyu Xu, and Chen Change Loy Computer Vision and Pattern Recognition Conference (CVPR), 2022 Paper | Code We investigate several useful techniques for real-world video super-resolution. |


|
Kelvin C.K. Chan, Shangchen Zhou, Xiangyu Xu, and Chen Change Loy Computer Vision and Pattern Recognition Conference (CVPR), 2022 Paper | Project We propose an improved video super-resolution algorithm, winner of the NTIRE 2021 video enhancement challenges. |


|
Xiangyu Xu, Chen Change Loy International Conference on Computer Vision (ICCV), 2021 (Oral Presentation) Paper | Code | Project We present a Transformer for 3D human texture estimation from a single image. |


|
Xiangyu Xu, Hao Chen, Francesc Moreno-Noguer, Laszlo A. Jeni, and Fernando De la Torre IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2021 Paper | Code We extend RSC-Net to videos and propose a human texture estimation model. |


|
Kelvin C.K. Chan, Xintao Wang, Xiangyu Xu, Jinwei Gu, and Chen Change Loy Computer Vision and Pattern Recognition Conference (CVPR), 2021 (Oral Presentation) Paper | Project We use StyleGAN for image super-resolution. |
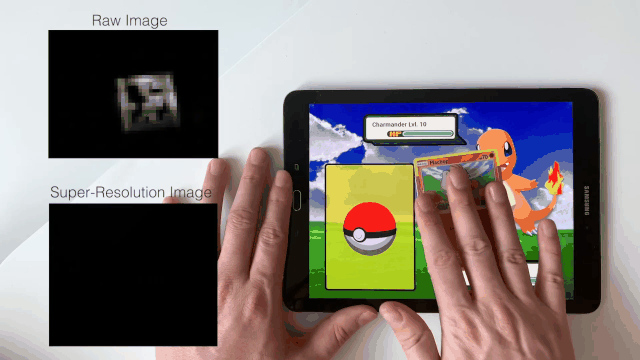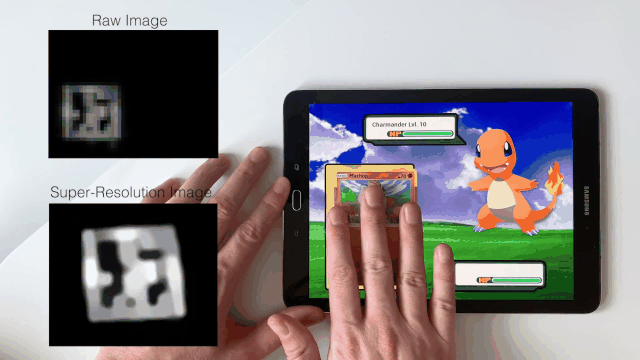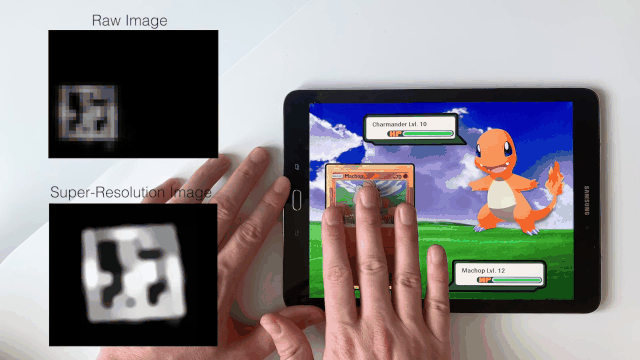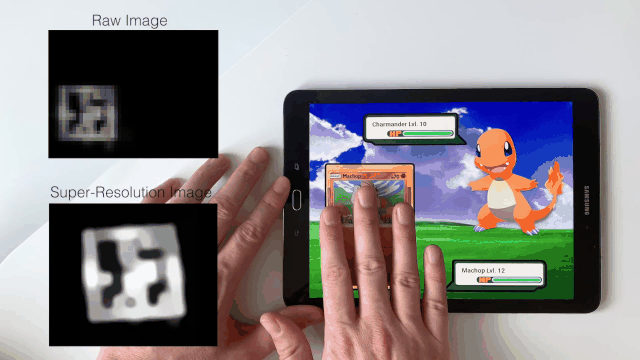
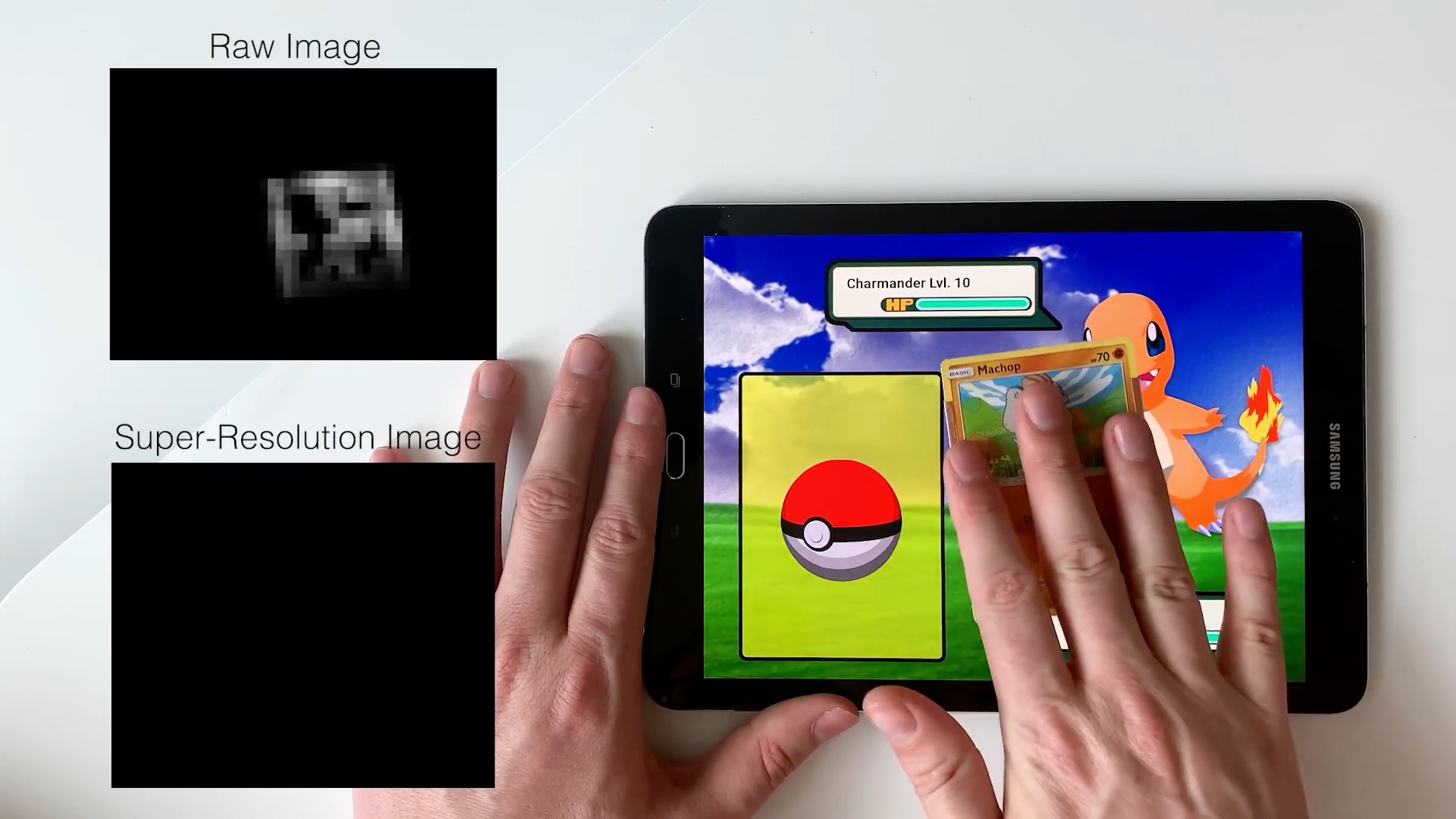
|
Sven Mayer, Xiangyu Xu, and Chris Harrison ACM Conference on Human Factors in Computing Systems (CHI), 2021 Paper | YouTube For the first time, super-resolution is applied to human-computer interaction. |


|
Xiangyu Xu, Yongrui Ma, Wenxiu Sun, and Ming-Hsuan Yang IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2020 Paper | Project | Code We improve the RawSR architecture and extend it to image dehazing and depth upsampling. |

|
Xiangyu Xu, Hao Chen, Francesc Moreno-Noguer, Laszlo A. Jeni, and Fernando De la Torre European Conference on Computer Vision (ECCV), 2020 Paper | Project | Code We propose a new algorithm for 3D human shape and pose estimation that is robust to low-resolution input. |


|
Xiangyu Xu, Muchen Li, Wenxiu Sun, and Ming-Hsuan Yang IEEE Transactions on Image Processing (TIP), 2020 Paper | Code We propose spatio-temporal deformable convolution kernels for image and video denoising. |


|
Xiangyu Xu, Yongrui Ma, Wenxiu Sun International Conference on Machine Learning (ICML), 2020 (Long Talk) Paper | Project We propose deep Robust PCA for joint image filtering. |


|
Xiangyu Xu*, Siyao Li*, Wenxiu Sun, Qian Yin, and Ming-Hsuan Yang Conference on Neural Information Processing Systems (NeurIPS), 2019 (Spotlight) Paper | Code We present the first nonlinear motion model for image interpolation. The method won the Champion of AIM 2019 video interpolation challenge. |


|
Xiangyu Xu, Yongrui Ma, Wenxiu Sun Computer Vision and Pattern Recognition Conference (CVPR), 2019 Paper | Code We present the first neural network for raw image based super-resolution. It works very well on real-world input. |


|
Wenqi Ren, Sifei Liu, Lin Ma, Qianqian Xu, Xiangyu Xu, Xiaochun Cao, Junping Du, Ming-Hsuan Yang IEEE Transactions on Image Processing (TIP), 2019 Paper We present a hybrid structure of CNN and RNN for low-light image enhancement. |


|
Xiangyu Xu, Deqing Sun, Sifei Liu, Wenqi Ren, Yu-Jin Zhang, Ming-Hsuan Yang, Jian Sun European Conference on Computer Vision (ECCV), 2018 Paper We present a CRF-based pipeline and a deep neural filter for rendering shallow depth-of-field effect with monocular camera. |


|
Yukang Gan*, Xiangyu Xu*, Wenxiu Sun, Liang Lin European Conference on Computer Vision (ECCV), 2018 Paper We propose to incorporate relative features, i.e., affinity, for monocular depth estimation. |


|
Xiangyu Xu, Jinshan Pan, Yu-Jin Zhang, Ming-Hsuan Yang IEEE Transactions on Image Processing (TIP), 2018 Paper | Project We present a deep neural network to extract salient edges for blind image deblurring. |


|
Wenqi Ren*, Jingang Zhang*, Xiangyu Xu*, Lin Ma, Xiaochun Cao, Gaofeng Meng, Wei Liu IEEE Transactions on Image Processing (TIP), 2018 Paper We exploit a neural network to perform haze removal for videos. |


|
Xiangyu Xu, Deqing Sun, Jinshan Pan, Yu-Jin Zhang, Hanspeter Pfister, Ming-Hsuan Yang International Conference on Computer Vision (ICCV), 2017 Paper | Project We present the first deep neural network for blind image super-resolution. |
|
Ruofeng Mei, PhD (XJTU, 2024-present)
|
|
Website template from here |